
大规模主题模型:对Spark LDA算法的改进
为了关注分布式计算,该阅读哪些资讯文章呢?这些问题都能够被话题模型所解答。这篇文章将要讨论Spark1.4和1.5使用强大的隐含狄利克雷分布(LatentDirichletAllocation,LDA)算法对话题模型的性能提升。...
为了关注分布式计算,该阅读哪些资讯文章呢?这些问题都能够被话题模型所解答。这篇文章将要讨论Spark1.4和1.5使用强大的隐含狄利克雷分布(LatentDirichletAllocation,LDA)算法对话题模型的性能提升。...
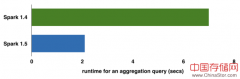
ApacheSpark社区刚刚发布了1.5版本,大家一定想知道这个版本的主要变化,这篇文章从DataFrame执行后端优化(Tungsten第一阶段)、DataFrameSQLHive、机器学习MLlib等角度告诉你答案。...

在这篇文章中,你将看到ApacheSpark可以用于机器学习的任务,如logisticregression。虽然这只是非分布式的单机环境的Scalashelldemo,但是Spark的真正强大在于分布式下的内存并行处理能力。...

内存计算引擎相对于传统数据处理引擎,最大的革新是基于LLVM编译器的动态代码生成技术,这篇文章将介绍现在的产品和技术是如何使用LLVM编译器来动态生成执行代码的,从而实现真正意义上的内存计算,及认识LLVM技术本身。...

对于1个年仅5岁的开源项目来说,其远谈不上尽善尽美,就比如文档相关。这篇文章翻译自SparkProgrammingGuide,选取了其中使用Python的部分。...

越来越多的设备使用无线传感器,这要求工程师通过像Matlab这类的软件做出HTTP请求,如GET、POST等,在这里可以通过使用cURL、urlread实现简单的HTTP操作。当然如若想使用更高级的功能,也可以选择urlread2。...

当下已活跃在Hortonworks、IBM、Cloudera、MapR和Pivotal等众多知名大数据公司,更拥有Spark SQL、Spark Streaming、MLlib、GraphX等多个相关项目。那么如此多的关注下,Spark又会有什么样的变化,下面看Spark 1.2版本新特性。...